Overgrowth, Pruning and Infantile Amnesia
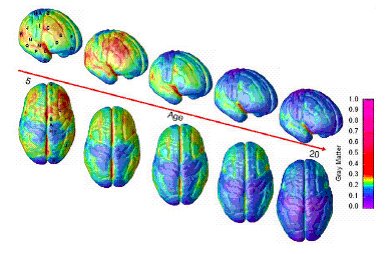 As discussed yesterday, the current issue of Nature contains an article showing that the smartest children are those whose cortical thickness follows a specific trajectory, of initial thickening and then rapid thinning. These processes are hypothesized to map on to a period of myelination and then of pruning, but the exact mechanisms are unknown.
As discussed yesterday, the current issue of Nature contains an article showing that the smartest children are those whose cortical thickness follows a specific trajectory, of initial thickening and then rapid thinning. These processes are hypothesized to map on to a period of myelination and then of pruning, but the exact mechanisms are unknown.Can computational modeling provide any insights into what patterns of myelination and pruning are most effective? One clue comes from a study by Meilijson and Ruppin in a 1998 issue of Neural Computation. The authors show that to maximize the network's signal to noise ratio, and assuming that there is some upper metabolic constraint on neural processing (modeled as limited total number of synapses), synaptic pruning is effective if one follows a "minimal value" function, in which one deletes all synapses with magnitude below some threshold and leaves all others intact. On the other hand, if one assumes that the upper metabolic constraint is the total amount of synaptic efficacy that can be distributed through the network, a "compressing deletion" pruning strategy is best, in which the all synapses with efficacy above some threshold are reduced by a constant amount, and then all others are deleted. The authors describe that both probably apply in the brain, in which the relative importance of each constraint may determine which actual pruning strategy is used. This likely also differs between brain regions.
The authors' crucial finding is that given these metabolic constraints, the best pruning strategy is actually advantageous as compared to a fully connected "infant" network. In other words, an optimally pruned network will have more neurons than an unpruned network, although they both have roughly the same number of synapses or amount of synaptic efficacy. In the authors' own words, "the conclusion is that an organism that first overgrows synapses in a large network and then judiciously prunes them can store many more memories than another adult organism that uses the same synaptic resources but settles for the adult synaptic density in infancy."
Although the metabolic efficiency is improved, this comes at a price, as discovered by the authors in simulating pruning in the midst of learning (just as actually occurs in childhood). Adult networks that undergo synaptic pruning actually lose the ability to retrieve the earliest memories. In humans, this phenomenon is known as "childhood amnesia," in which memories before the age of 5 are hazy, and those before 3 are almost completely inaccessible. This amnesia emerges from the networks because the earliest memories are stored in a highly distributed fashion, relying on many different neurons, while later memories are stored in a more sparse format. Therefore, early memories are more degraded by the pruning strategy because of sheer probability: more neurons participate in their representation, so they are more easily affected by changes to the network.
These computational models provide a fascinating insight into the developmental trends discussed yesterday. Is it possible that the smartest children, whose cortex goes from relatively thin, to maximally thick, and then back again to relatively thin, would actually show less infantile amnesia than their mid-intelligence peers, whose cortices are initially thicker? If so, one wonders whether this might be causal as opposed to merely correlational with increased IQ measures, although this is purely speculative.
In botany, pruning induces "rejuvenation" at the pruned nodes. Perhaps neural pruning results in an overall decrease in cortical thickness, which is equivalent to why pruned plants will receive more sunlight, and yet also increases the efficacy of existing circuits, in the same way that pruned plants will yield more flowers and fruit. The metaphor is of course purely anecdotal, but one wonders whether these similarities might be more than mere coincidence.
This study has several broad implications for the field of artificial intelligence in general. First, should we limit the total number of synaptic connections/total amount of synaptic efficacy, to plausibly simulate biological metabolic energy consumption constraints? Second, given that an optimally pruned network is superior to all other networks with an equivalent number of synapses, and given that current computing power can only support some non-infinite number of synapses, should we simulate pruning in order to increase the effectiveness of machine learning?
Finally, is it possible to further increase network efficiency through recursively overgrowing and then pruning synaptic connections? There is some evidence that such recursive processes may occur in humans, as well; Jay Giedd discovered "a second wave" of neural overgrowth during puberty, which is followed by a second pruning process.
Related Posts:
The Structural Signature of Intelligence
Tuned and Pruned: Synaesthesia
Modeling Neurogenesis
posted by Chris Chatham at 7:06:00 AM. Now go to the current Developing Intelligence blog!
3 comments
![]()
![]()




















{kind=link}
{kind=link}